
El análisis de conglomerados en Python es una técnica fundamental en la minería de datos y el aprendizaje automático que se utiliza para identificar grupos o conglomerados dentro de un conjunto de datos. Se aplica ampliamente en diversos ámbitos, incluidos el marketing, la biología, el procesamiento de imágenes y la segmentación de clientes. Python, con su rico ecosistema de bibliotecas, proporciona herramientas poderosas para realizar análisis de clústeres de manera eficiente y efectiva. Para empezar, discutiremos los conceptos esenciales del análisis de conglomerados. La agrupación tiene como objetivo agrupar objetos similares en función de sus características y relaciones intrínsecas. Estos grupos se forman de tal manera que los objetos dentro del mismo grupo son más similares entre sí que a los de otros grupos. La elección del algoritmo de agrupamiento y las métricas de evaluación depende de la naturaleza de los datos y del problema específico en cuestión.
Python ofrece varias bibliotecas potentes para el análisis de conglomerados, incluidas scikit-learn, scipy y K-means. Scikit-learn proporciona un conjunto completo de herramientas para el aprendizaje automático, incluidos varios algoritmos de agrupación en clústeres, como K-means, DBSCAN y agrupación jerárquica. Scipy, una biblioteca de informática científica, ofrece funciones para realizar agrupaciones jerárquicas y cálculos de distancia. K-means es un algoritmo popular que se utiliza para dividir datos en un número predefinido de grupos. Lea el siguiente artículo curado sobre tendencias para obtener más información sobre el mejor análisis de clústeres en Python, el mejor curso de Python en clústeres y el curso de Python en clústeres en línea.





¿Qué es el análisis de conglomerados?
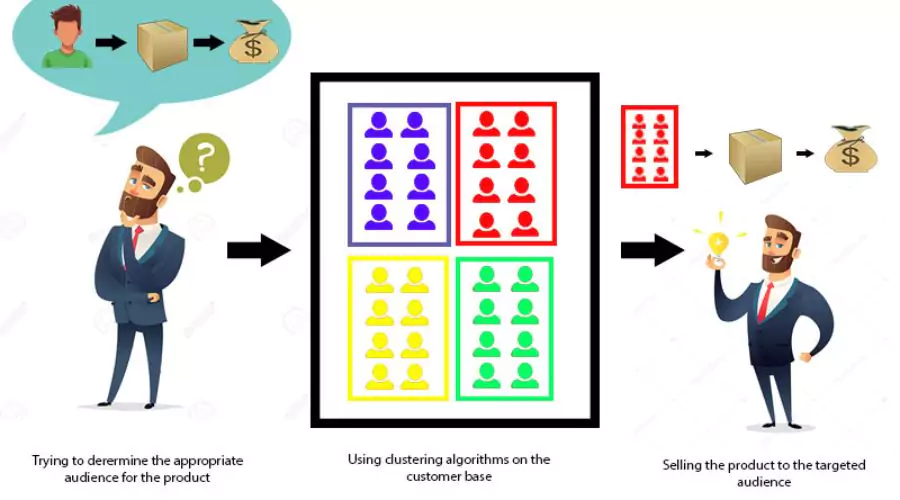
¿Qué es el análisis de conglomerados? | policía de neón
Análisis de conglomerados en Python es el proceso de dividir un conjunto de datos en grupos, o clusters, en función de la similitud o disimilitud de los objetos que contiene. El objetivo es garantizar que los objetos dentro del mismo grupo sean más similares entre sí que los de otros grupos. El análisis de conglomerados tiene una amplia gama de aplicaciones, incluida la segmentación de clientes, el procesamiento de imágenes, el análisis de datos biológicos y la detección de anomalías. Para comprender el análisis de conglomerados, es importante estar familiarizado con los conceptos y la terminología clave. Introducimos términos como conglomerados, métricas de distancia y centroides. Las métricas de distancia, como la distancia euclidiana y de Manhattan, miden la similitud entre objetos. El centroide representa el punto central de un grupo. Además, analizamos la validez de los grupos y las métricas de evaluación para evaluar la calidad de los resultados de la agrupación.
Preprocesamiento de datos para análisis de conglomerados
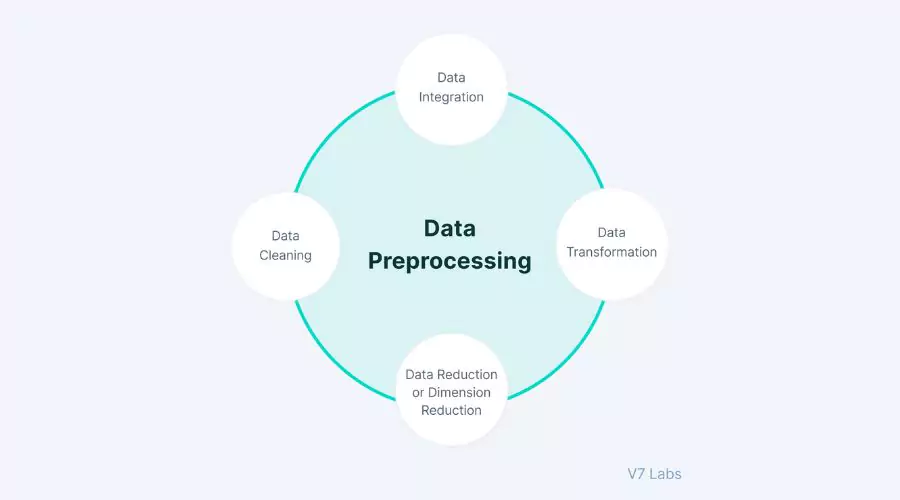
Preprocesamiento de datos para análisis de conglomerados | policía de neón
Preprocesamiento de datos juega un papel crucial en el análisis de conglomerados en Python. Profundizamos en técnicas para el manejo de valores faltantes, valores atípicos y variables categóricas. Estos pasos de preprocesamiento garantizan que los datos estén en un formato adecuado para la agrupación. La selección de características es esencial en el análisis de conglomerados para identificar las características más relevantes para la agrupación. Exploramos técnicas como el Análisis de Componentes Principales (PCA) y t-SNE para la reducción de dimensionalidad, que pueden ayudar a visualizar datos de alta dimensión y mejorar el rendimiento de la agrupación.
Algoritmos e implementaciones de agrupación en clústeres populares en Python
Implementaciones y algoritmos de agrupamiento populares en Python | policía de neón
K-significa agrupación
K-medias agrupación es uno de los algoritmos de agrupación en clústeres basados en particiones más utilizados. Explicamos los principios detrás de K-means y demostramos su implementación utilizando la biblioteca scikit-learn. También discutimos estrategias para seleccionar el número óptimo de clusters.
Agrupación jerárquica
Agrupación jerárquica es un poderoso algoritmo que organiza los datos en una jerarquía de grupos. Explicamos los conceptos de agrupación jerárquica aglomerativa y divisiva y mostramos su implementación con la biblioteca scipy. Los dendrogramas se presentan como representaciones visuales de resultados de agrupamiento jerárquico.
Agrupación basada en densidad
Agrupación basada en densidad Los algoritmos, como DBSCAN, son adecuados para descubrir grupos de formas arbitrarias. Presentamos el algoritmo DBSCAN y demostramos su implementación utilizando scikit-learn. También discutimos cómo interpretar y evaluar los resultados de DBSCAN.
Métricas de evaluación interna
evaluando La calidad de los resultados de la agrupación es crucial para evaluar la eficacia del algoritmo. Explicamos métricas de evaluación interna como el Coeficiente de Silueta y el Índice Davies-Bouldin, que miden la cohesión y separación de los clusters. Mostramos su implementación en Python.
Métricas de evaluación externa
En algunos casos, métricas de evaluación externa se utilizan cuando hay etiquetas de verdad sobre el terreno disponibles. Introducimos métricas como el índice de Rand ajustado (ARI) y la información mutua (MI), que evalúan la concordancia entre los resultados de la agrupación y la verdad fundamental. Demostramos el uso de métricas de evaluación externa en Python.
Conclusión
En este artículo, hemos explorado el mundo de análisis de conglomerados en Python y su importancia en Descubriendo patrones y estructuras. dentro de conjuntos de datos. Comenzamos por comprender los conceptos centrales del análisis de conglomerados, incluida la definición de conglomerados, métricas de distancia y centroides. Luego profundizamos en los pasos de preprocesamiento necesarios para preparar los datos para agrupaciones, como el manejo de valores faltantes, valores atípicos y variables categóricas, así como técnicas de selección de características y reducción de dimensionalidad. Exploramos algoritmos de agrupamiento populares disponibles en Python, incluidos K-means, agrupamiento jerárquico y agrupamiento basado en densidad. A través de ejemplos prácticos e implementaciones utilizando bibliotecas como scikit-learn y scipy, aprendimos cómo aplicar estos algoritmos a nuestros conjuntos de datos e interpretar los grupos resultantes. También discutimos estrategias para determinar el número óptimo de conglomerados y evaluamos la calidad de los resultados de la agrupación utilizando métricas de evaluación internas y externas. Esto es todo lo que debes saber sobre el análisis de conglomerados en Python. Además, visite el sitio web oficial de Trending Cult para obtener más información sobre el análisis de conglomerados en Python.
preguntas frecuentes