
L'analyse de cluster en Python est une technique fondamentale d'exploration de données et d'apprentissage automatique utilisée pour identifier des groupes ou des clusters au sein d'un ensemble de données. Il est largement appliqué dans divers domaines, notamment le marketing, la biologie, le traitement d’images et la segmentation client. Python, avec son riche écosystème de bibliothèques, fournit des outils puissants pour effectuer une analyse de cluster de manière efficace et efficiente. Pour commencer, nous aborderons les concepts essentiels de l’analyse typologique. Le clustering vise à regrouper des objets similaires en fonction de leurs caractéristiques et relations intrinsèques. Ces clusters sont formés de telle manière que les objets d’un même cluster sont plus similaires les uns aux autres qu’à ceux des autres clusters. Le choix de l'algorithme de clustering et des métriques d'évaluation dépend de la nature des données et du problème spécifique à résoudre.
Python propose plusieurs bibliothèques puissantes pour l'analyse de cluster, notamment scikit-learn, scipy et K-means. Scikit-learn fournit un ensemble complet d'outils pour l'apprentissage automatique, notamment divers algorithmes de clustering tels que K-means, DBSCAN et le clustering hiérarchique. Scipy, une bibliothèque de calcul scientifique, propose des fonctions permettant d'effectuer des regroupements hiérarchiques et des calculs de distance. K-means est un algorithme populaire utilisé pour partitionner les données en un nombre prédéfini de clusters. Lisez l'article suivant organisé par un culte des tendances pour en savoir plus sur la meilleure analyse de cluster en Python, le meilleur cours de cluster Python et le cours de cluster Python en ligne.





Qu’est-ce que l’analyse cluster ?
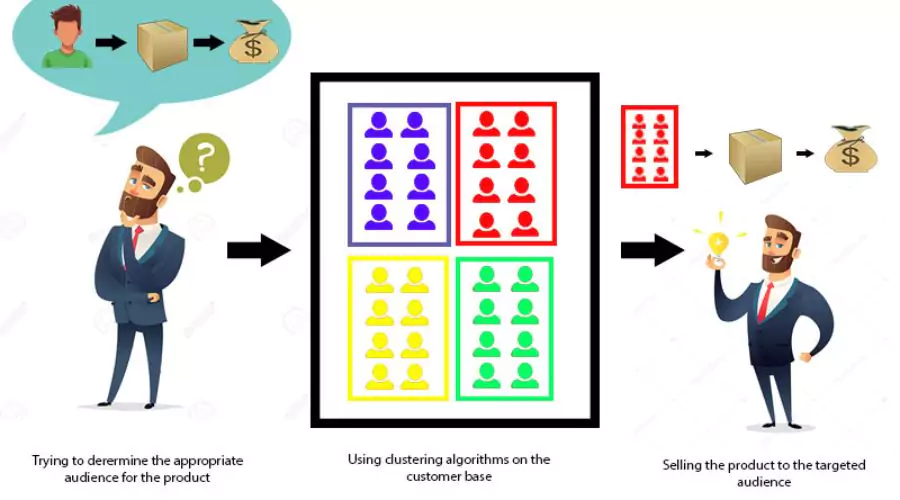
Qu’est-ce que l’analyse cluster ? | Néonpolice
Analyse de cluster en Python est le processus de division d'un ensemble de données en groupes, ou clusters, en fonction de la similitude ou de la dissemblance des objets qu'il contient. L'objectif est de garantir que les objets d'un même cluster sont plus similaires les uns aux autres qu'à ceux des autres clusters. L'analyse groupée a un large éventail d'applications, notamment la segmentation des clients, le traitement d'images, l'analyse de données biologiques et la détection d'anomalies. Pour comprendre l’analyse typologique, il est important de se familiariser avec les concepts et la terminologie clés. Nous introduisons des termes tels que clusters, mesures de distance et centroïdes. Les mesures de distance, telles que la distance euclidienne et la distance de Manhattan, mesurent la similarité entre les objets. Le centre de gravité représente le point central d'un cluster. De plus, nous discutons de la validité des clusters et des mesures d'évaluation pour évaluer la qualité des résultats du clustering.
Prétraitement des données pour l'analyse de cluster
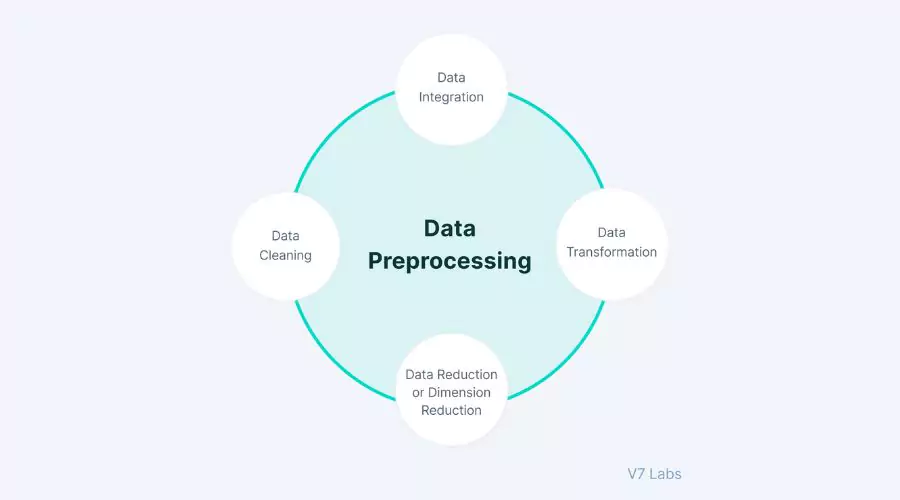
Prétraitement des données pour l'analyse de cluster | Néonpolice
Prétraitement des données joue un rôle crucial dans l’analyse de cluster en Python. Nous approfondissons les techniques de gestion des valeurs manquantes, des valeurs aberrantes et des variables catégorielles. Ces étapes de prétraitement garantissent que les données sont dans un format approprié pour le clustering. La sélection des fonctionnalités est essentielle dans l'analyse de cluster pour identifier les fonctionnalités les plus pertinentes pour le clustering. Nous explorons des techniques telles que l'analyse en composantes principales (ACP) et le t-SNE pour la réduction de dimensionnalité, qui peuvent aider à visualiser des données de grande dimension et à améliorer les performances de clustering.
Algorithmes de clustering et implémentations populaires en Python
Algorithmes de clustering et implémentations populaires en Python | Néonpolice
Clustering K-means
K-means clustering est l’un des algorithmes de clustering basés sur le partitionnement les plus utilisés. Nous expliquons les principes derrière K-means et démontrons sa mise en œuvre à l'aide de la bibliothèque scikit-learn. Nous discutons également des stratégies permettant de sélectionner le nombre optimal de clusters.
Classification hiérarchique
Classification hiérarchique est un algorithme puissant qui organise les données dans une hiérarchie de clusters. Nous expliquons les concepts de clustering hiérarchique agglomératif et diviseur et présentons leur implémentation avec la bibliothèque scipy. Les dendrogrammes sont présentés comme des représentations visuelles des résultats du regroupement hiérarchique.
Clustering basé sur la densité
Clustering basé sur la densité les algorithmes, tels que DBSCAN, conviennent à la découverte de groupes de formes arbitraires. Nous introduisons l'algorithme DBSCAN et démontrons sa mise en œuvre à l'aide de scikit-learn. Nous discutons également de la manière d’interpréter et d’évaluer les résultats DBSCAN.
Paramètres d'évaluation interne
Évaluation la qualité des résultats de clustering est cruciale pour évaluer l’efficacité de l’algorithme. Nous expliquons les mesures d'évaluation internes telles que le coefficient Silhouette et l'indice Davies-Bouldin, qui mesurent la cohésion et la séparation des clusters. Nous présentons leur implémentation en Python.
Paramètres d'évaluation externe
Dans certains cas, paramètres d'évaluation externe sont utilisés lorsque des étiquettes de vérité terrain sont disponibles. Nous introduisons des mesures telles que l'indice Rand ajusté (ARI) et l'information mutuelle (MI), qui évaluent l'accord entre les résultats du regroupement et la vérité terrain. Nous démontrons l'utilisation de métriques d'évaluation externes en Python.
Conclusion
Dans cet article, nous avons exploré le monde de l'analyse par grappes en Python et sa signification dans découvrir des modèles et des structures au sein des ensembles de données. Nous avons commencé par comprendre les concepts fondamentaux de l'analyse cluster, notamment la définition des clusters, les mesures de distance et les centroïdes. Nous avons ensuite approfondi les étapes de prétraitement nécessaires à la préparation des données pour les regroupements, telles que la gestion des valeurs manquantes, des valeurs aberrantes et des variables catégorielles, ainsi que les techniques de sélection de caractéristiques et de réduction de dimensionnalité. Nous avons exploré les algorithmes de clustering populaires disponibles en Python, notamment les K-means, le clustering hiérarchique et le clustering basé sur la densité. Grâce à des exemples pratiques et à des implémentations utilisant des bibliothèques telles que scikit-learn et scipy, nous avons appris à appliquer ces algorithmes à nos ensembles de données et à interpréter les clusters résultants. Nous avons également discuté de stratégies pour déterminer le nombre optimal de clusters et évalué la qualité des résultats de clustering à l'aide de mesures d'évaluation internes et externes. C'est tout ce que vous devez savoir sur l'analyse de cluster en Python. De plus, visitez le site officiel du culte Trending pour en savoir plus sur l'analyse de cluster en Python.
FAQ